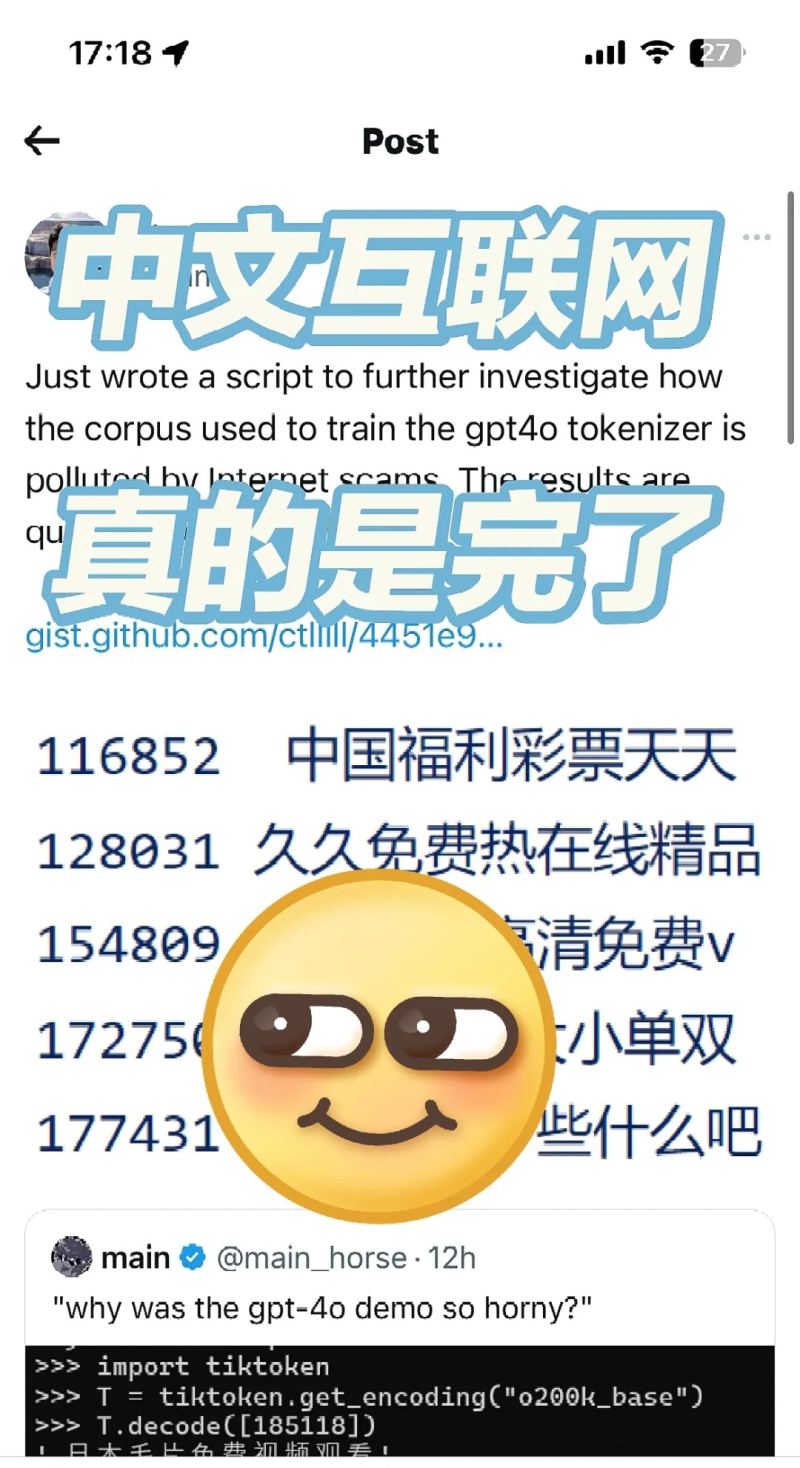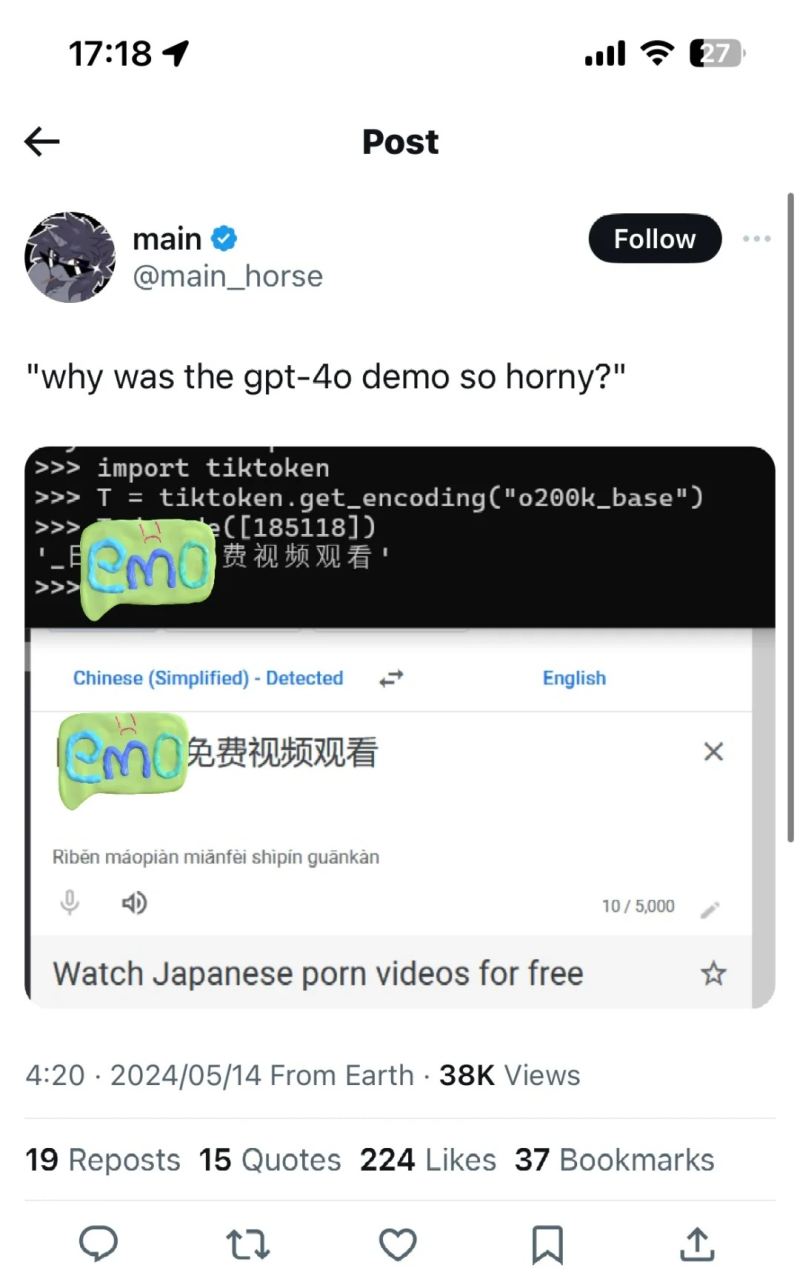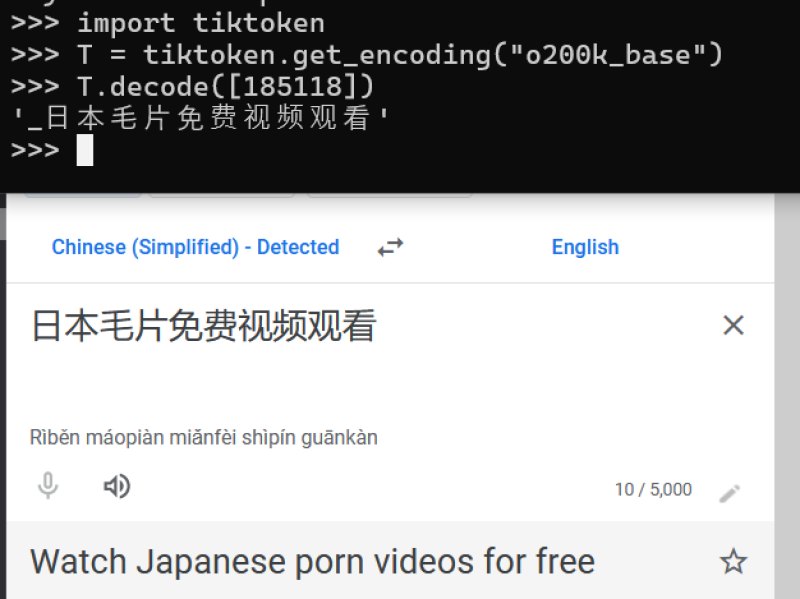
虽然中文互联网被污染了是一个既成事实,但是没想到会以这种方式呈现出来。
刚刚在X上看到有人挖掘GPT-4o的词汇表,然后发现里面有很多不可描述的词汇。原理是GPT-4o对多语言进行了针对训练,应该是增加了使用的互联网数据。然后在训练分词器的时候会把出现的频繁的词合并成一个词汇。
比如说之前中文数据少的时候每个词都是被分割成一个一个汉字了,所以日本电影被分割成日 本 电 影四个字。但是现在因为此类表达出现的频率过大,大到模型认为值得为他它专门在词汇表里增加一个词汇有时间了给大家详细讲讲LLM的分词是怎么实现的)。
所以造成这种现象的原因是中文网络现在基本上被分割成一片一片的app的自留地。而互联网上则只剩下内容农场,垃圾站,以及为黄赌毒引流的网站了。
从某种意义上来说这也是国产LLM的崛起机会?因为国产app里面有大量Openai接触不到的训练数据。
– 推特的简中内容完全没法看,搜索已经完全废掉了,任何关键词搜出来都是黄片。